
2022. 1. 27. 19:04ㆍ🔴 ETC/Tools

소개
puppeteer은 구글에서 만든 노드 라이브러리로 Headless Chrome 또는 Chrominum을 제어할 수 있다.
* headless?
백그라운드에서 작동하는 브라우저이다.
때문에 일반 사용자가 브라우저를 사용할 때처럼 화면에 창이 시각적으로 보이지 않는다.
보이는 화면은 없지만, 실제로 띄워진 화면에서 화면 테스트를 하듯이 테스트를 할 수 있다.
puppeteer에서는 옵션 설정을 통해 headless모드와 non-headless모드 둘 다 사용할 수 있다.
const browser = await puppeteer.launch({ headless: false }); // default is true우리는 puppeteer를 통해 다음과 같은 것들을 할 수 있다 :
- 화면을 스크린샷하거나 PDF를 생성할 수 있다.
- SPA(Single-Page Application) 을 크롤링하여 사전에 콘텐츠를 랜더링 할 수 있다.
(ex. SSR - SSR에 관한 내용은 https://d2.naver.com/helloworld/7804182 참고)
- 자동화된 UI 테스트 실행 : Form을 submit, input을 입력 ...
- 최신 버전의 크롬에서 자동화된 테스트 환경을 만들 수 있다.
- timeline trace를 통해 퍼포먼스 이슈를 진단할 수 있다.
- 크롬 확장 프로그램을 테스트할 수 있다.
(더 자세한 예시들은 맨 아래 영상 참고)
구조
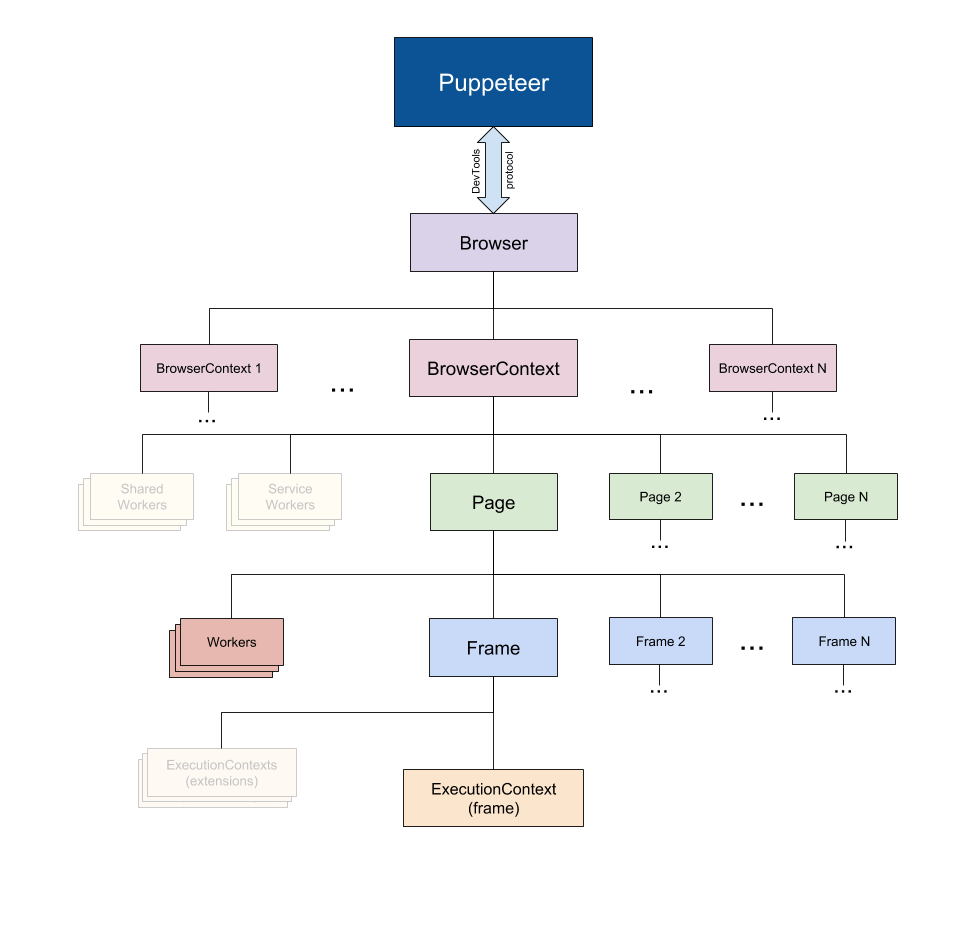
puppeteer API는 이런 식으로 계층적인 구조로 구성되어 있고, 실제 브라우저 구성요소처럼 되어있다.
- Puppeteer는 크롬의 DevTools Protocol를 사용하여 브라우저를 컨트롤한다.
- Browser 인스턴스는 다수의 browser context를 가질 수 있다.
- BrowserContext 인스턴스는 브라우저의 세션을 규정하며 다수의 Page를 가질 수 있다.
- Page는 최소 하나의 Frame을 가지고 있어야 한다 (= 메인 Frame). 추가적으로 iframe이나 frame 태그를 통해 다른 Frame들을 가질 수 있다.
- Frame은 최소 하나의 ExecutionContext를 가지고 있어야 한다. 여기서 Frame의 자바스크립트가 실행된다.
- Worker는 하나의 ExecutionContext를 가지고 있으며 WebWorkers와 인터렉트 한다.
설치
npm i puppeteer
# or "yarn add puppeteer"Typescript으로 사용 (ver 7.0.1)
npm install --save-dev @types/puppeteer사용
1. https://example.com으로 이동하고 example.png라는 이름으로 스크린샷을 캡쳐해서 저장하기
<example.js>
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'example.png' });
await browser.close();
})();커맨드 라인 실행
node example.js-> pupppeteer은 800*600px 사이즈로 스크린샷을 캡처한다. Page.setViewport()로 해당 페이지의 사이즈를 커스텀 할 수 있다.
2. PDF 만들기
<hn.js>
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com', {
waitUntil: 'networkidle2',
});
await page.pdf({ path: 'hn.pdf', format: 'a4' });
await browser.close();
})();커맨드 라인 실행
node hn.js-> Page.pdf() 에서 pdf 저장 옵션들을 볼 수 있다.
3. 페이지 내에서 테스트 스크립트 실행하기
<get-dimensions.js>
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();커맨드 라인 실행
node get-dimensions.js-> Page.evaluate() 더 보기
사실 공식 깃헙에 있는 간단한 예시로는 실질적으로 puppeteer를 어떻게 사용할 수 있는지 알 수 없었다.
그러다가 공식 홈페이지에 올라온 영상을 보게 되었는데, puppeteer와 headless chrome에 대해 자세히 알아볼 수 있었다.
관련 영상
https://www.youtube.com/watch?v=lhZOFUY1weo
위는 puppeteer 공식 홈페이지에 업로드되어있는 puppeteer설명 영상이다.
영상에서 유용한 설명들은 아래에 화면 캡처와 함께 정리하였다 :

puppeteer는 백그라운드에서 실행되는 크롬 브라우저 + CDP (Chrome Devtool Protocol)가 베이스로 깔려있어 강력한 UI 테스트 도구로 볼 수 있다. 그리고 puppeteer가 제공하는 API를 통해 우리는 자동화 테스트 스크립트를 작성할 수 있다.
그리고 영상에서는 'Headless Chrome'을 특히나 강조했는데, 이를 통해서 다양한 테스트 및 기능을 사용해 볼 수 있어서이다.
그러면서 headless chrome을 실제로 어떻게 사용할 수 있는지 코드와 함께 보여주었다.
headless Chrome을 통해 우리가 할 수 있는 10가지 예시 :
1. Pre-rendering JS sites - 자바스크립트 애플리케이션을 pre-rendering 할 수 있다. (= 사전에 미리 HTML 파일을 만들어서 화면에 보여준다, 이에 관련해서는 https://velog.io/@dbfudgudals/pre-render 참고)
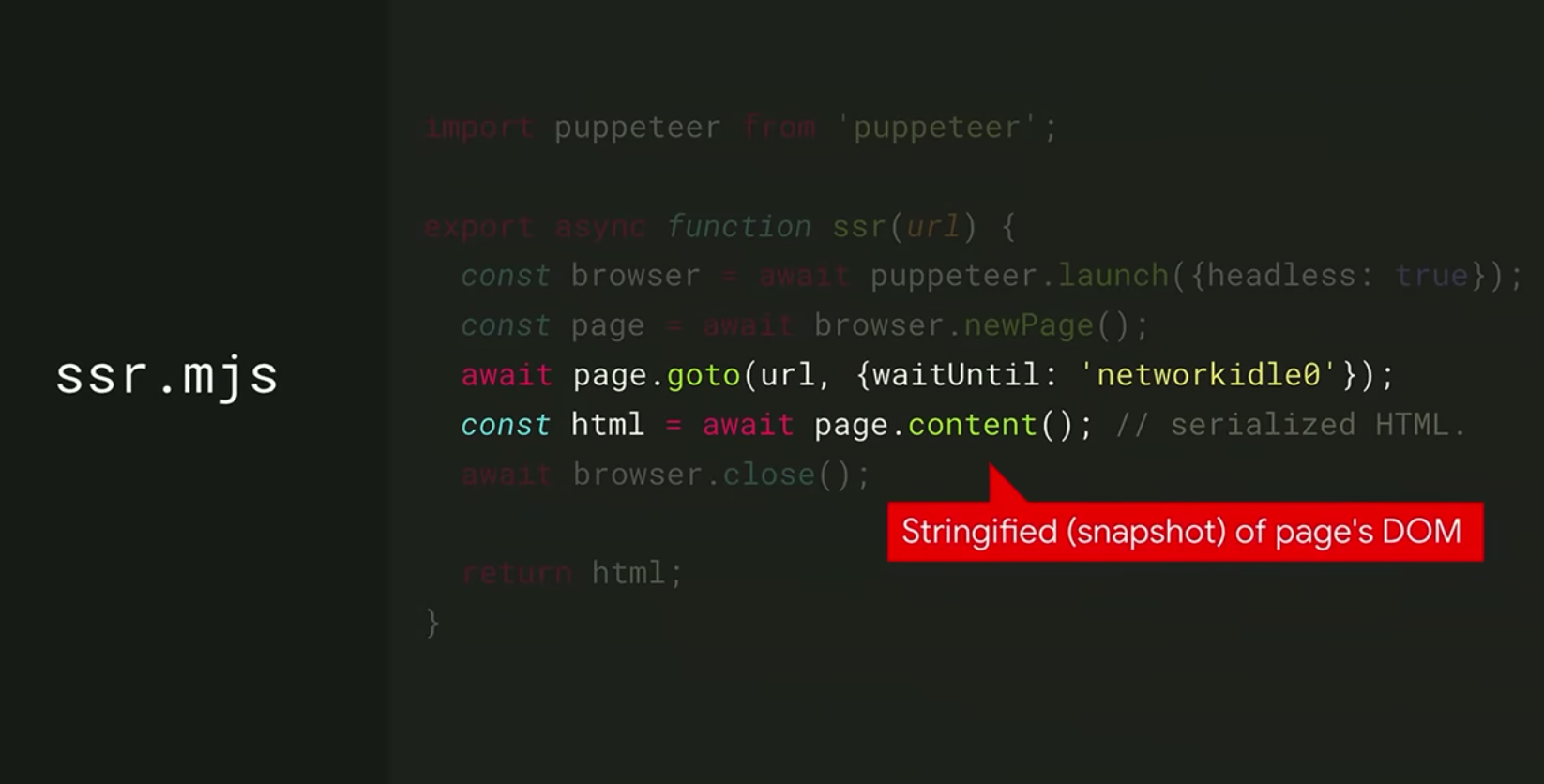
<div id="container"> </div>실제로 마크업에는 'container'라는 id의 div만 있어서 텅 빈 페이지인데, <srr.mjs>에서 해당 url의 콘텐츠를 가져와서 container에 넣어준다. 물론 headless로 진행되기 때문에 사용자는 외부 url로 가서 내용을 긁어오는 과정을 보지 못한다.

추가적으로 Map으로 url과 내용을 캐싱하여 내용을 더 빨리 로딩될 수 있도록 할 수도 있다.
2. verifying lazy loading is paying off - Code coverage API를 통해서 애플리케이션의 속도를 세세히 측정해 볼 수 있다.

여기서는 JS와 CSS 리소스가 페이지가 로딩될 때 어떻게 사용되고 있는지 확인할 수 있다.
3. A/B Testing - 코드를 수정할 필요 없이 puppeteer로 코드를 실시간으로 수정할 수 있다.
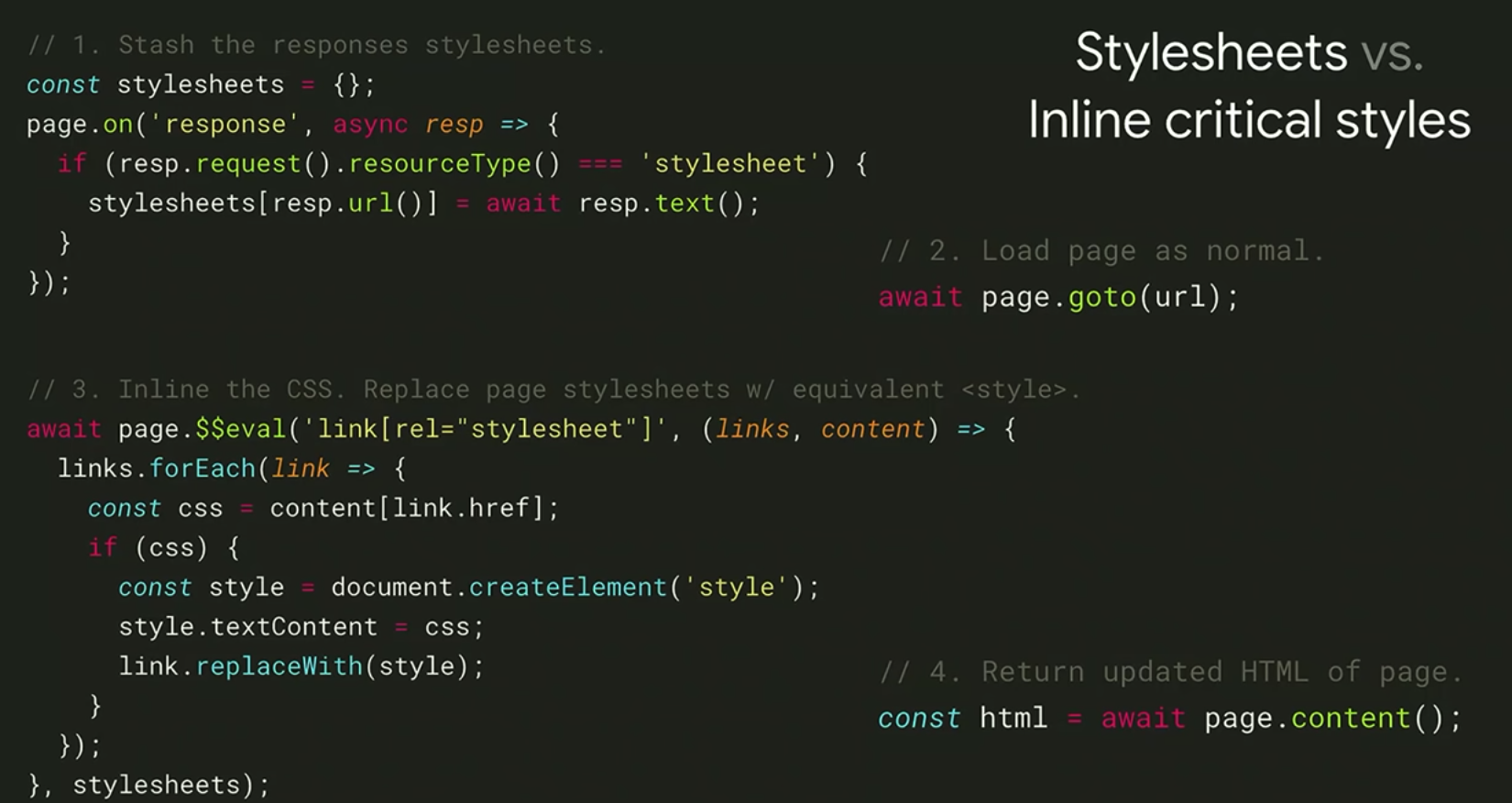
response를 받을 때 먼저 Stylesheet의 CSS text를 저장해둔다. 그리고 테스트하고 싶은 페이지로 가서, '$$'를 통해 (jQuery처럼 CSS selector를 사용할 수 있음) link태그들을 style태그로 바꾼 다음 아까 저장해둔 stylesheet 내용들로 채웠다.
4. Catch potential issues for the Google crawler - 구글 크롤러를 사용할 때 발생할 수 있는 이슈를 캐치할 수 있다.

puppeteer의 tracing API를 통해 애플리케이션에 사용한 JavaScript, CSS, API 등을 뽑아낼 수 있다. 현재 Chrome 버전에 맞게 코드를 짰는지 확인할 수 있다. (여기서는 Chrome 41이 지원하지 않는 것들을 써서 puppeteer가 잡아냈다)
5. Create PDFs - PDF를 만들 수 있다.

headless chrome과 puppeteer를 사용하여 원하는 형태의 PDF 파일을 만들어낼 수 있다. 여기서는 테스트 리포트 페이지를 headless 상태에서 생성하여 pdf로 만들었다.
6. Make you browser talk - 브라우저의 web speech synthesis API + puppeteer
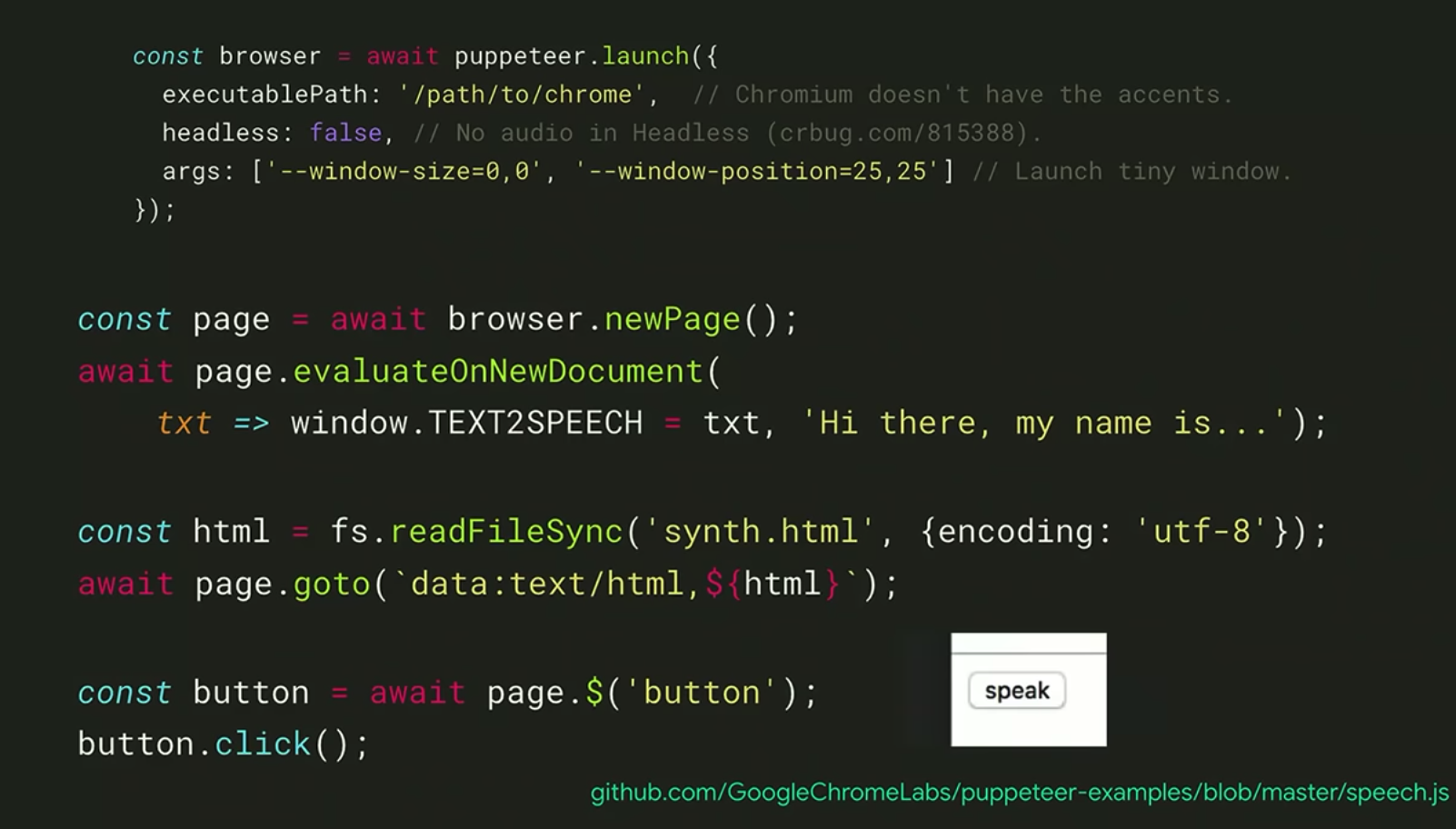
web speech synthesis API은 headless인 상태에서 지원하지 않기 때문에 option을 false로 세팅하고, puppeteer로 페이지 내 버튼을 자동 클릭하게 만들어서 해당 텍스트를 읽게 하였다. (사실 이 부분은 그냥 puppeteer와 브라우저의 API를 조합하여 사용한 예시로 보면 될 것 같다)
7. Test a Chrome extension - 크롬 확장 프로그램을 테스트할 수 있다.

실제로 Unit test를 하는 크롬 확장 프로그램인 'Lighthouse'는 puppeteer를 사용하여 테스트를 할 수 있도록 하였다.
8. Crawl a SPA - SPA로 된 페이지를 크롤링할 수 있다.

예시에서는 puppeteer의 $$를 통해 페이지 내의 링크를 가져와 각 페이지의 스크린샷을 모아서 보여주었다.
9. Verify service worker offline caching - Service Worker가 오프라인 상태에서 캐싱을 하고 있는지 확인해볼 수 있다.
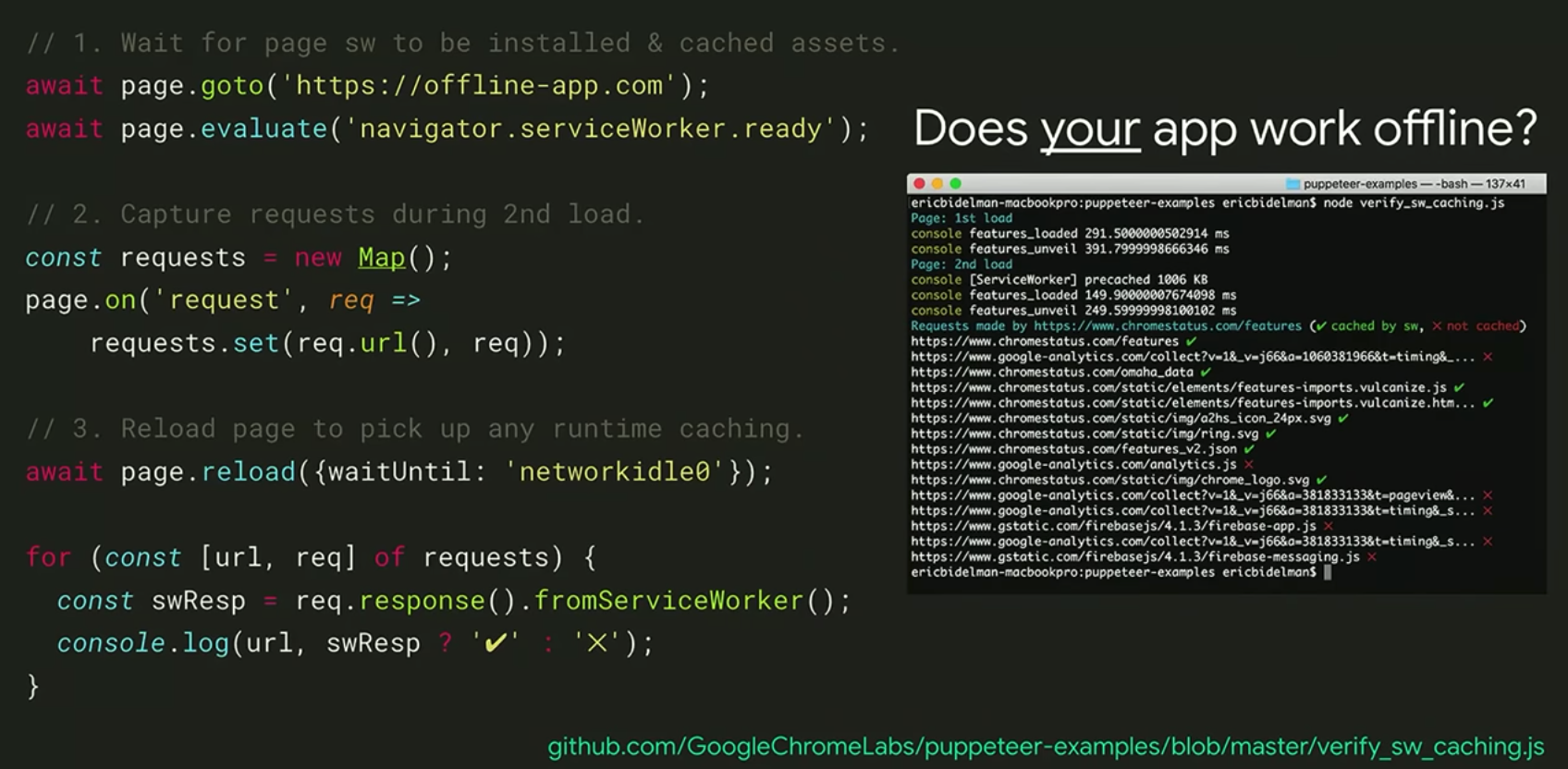
Service Worker는 오프라인 상태(사용자가 페이지를 닫은 상태)에서도 캐싱을 하기 때문에, 동기화나 푸시 알림을 하도록 해준다. (Service Worker 참고 : https://so-so.dev/web/service-worker/)
만약 캐싱이 제대로 되지 않는다면 이미지가 깨지거나 404 에러를 보여줄 수 있기 때문에, 실제로 캐싱이 잘 되고 있는지 puppeteer로 Service Worker의 response를 가려내어 확인하는 로직을 짤 수 있다.
10. 그 외 puppeteer에서 지원하는 API들...
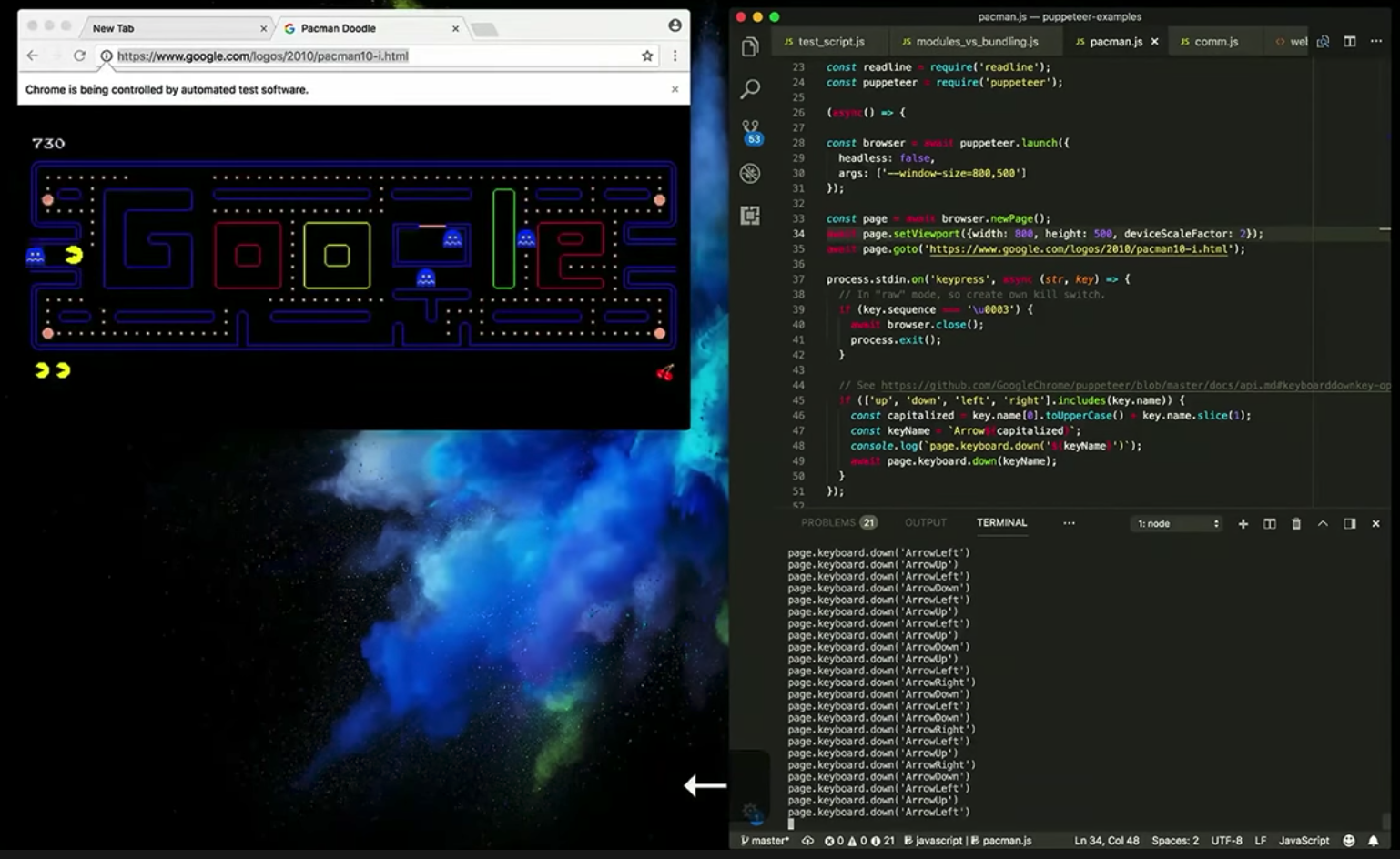
영상에서는 구글 팩맨 게임을 Node에서 실행하는 것을 보여주었다. puppeteer에서는 keyboard API, touch API 등을 지원한다.
Puppeteer Official Website : https://pptr.dev/
Puppeteer Official Homepage : https://developers.google.com/web/tools/puppeteer
Puppeteer Github : https://github.com/puppeteer/puppeteer
'🔴 ETC > Tools' 카테고리의 다른 글
| [test tool 2-2] Jest+React+TypeScript - 이미 개발된 코드에 unit test를 적용해보자 (+코드 리팩토링은 덤) (0) | 2023.11.07 |
|---|---|
| [test tool 2-1] Jest+React+TypeScript - 이미 개발된 코드에 unit test를 적용해보자 (+코드 리팩토링은 덤) (0) | 2023.11.05 |